Paper link | Note link | Code link | NeurIPS 2023
本研究使用 Semantic IDs 來檢索用戶的推薦項目。
本研究不使用查詢嵌入來檢索前幾名候選項目。
相反,它為每個項目建立一個 Semantic IDs,並使用基於 Transformer 的 seq2seq 模型來預測用戶將與之互動的下一個項目的 Semantic IDs。

通常,推薦系統使用檢索和排序策略來幫助用戶發現感興趣的內容:
這篇論文提出了「Transformer Index for GEnerative Recommenders(TIGER)」,這是一個生成式檢索型推薦框架,為每個項目分配語義ID,並訓練檢索模型來預測給定用戶可能會互動的項目的 Semantic ID。
TIGER 提供了兩個主要優勢:

Semantic ID 設定為長度為 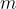 的代碼字元組。
的代碼字元組。
每個代碼字來自不同的 codebook。
因此,Semantic ID 可以唯一地表示的項目數量等於 codebook 大小的乘積。

生成 Semantic ID 的過程從獲得來自預訓練 encoder 的語義嵌入 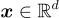 開始。
開始。
RQ-VAE 學習潛在表示 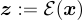 。
。
在第 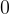 級(
級(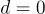 ),初始殘差定義為
),初始殘差定義為 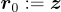 。
。
對於第  級,過程重複
級,過程重複 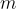 次:
次:
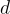 ,都有一個 codebook
,都有一個 codebook 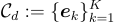 ,其中
,其中 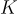 是 codebook 的大小。
是 codebook 的大小。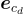 被表示為
被表示為 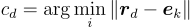 。
。注意,他們選擇對每個 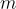 級別使用大小為
級別使用大小為 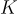 的獨立 codebook。
的獨立 codebook。
然後,計算量化表示 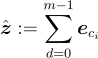 ,並將其傳遞給 decoder 以重建輸入
,並將其傳遞給 decoder 以重建輸入 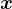 。
。
RQ-VAE 損失函數聯合訓練 encoder、decoder 和 codebook:
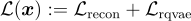
其中
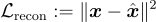
且
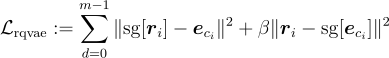
推薦系統嘗試從序列  中預測下一個項目
中預測下一個項目 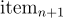 。
。
本研究改為直接預測下一個項目的 Semantic ID。
給定一個項目序列 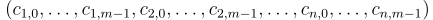 ,預測
,預測 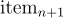 的本研究改為直接預測下一個項目的 Semantic ID,即
的本研究改為直接預測下一個項目的 Semantic ID,即  。
。
他們在來自 Amazon Product Reviews dataset 的三個公共實際基準上測試了他們的框架。
在這裡,他們使用了三個類別:“美容”,“體育和戶外”以及“玩具和遊戲”。
對於語義 encoder,使用了預訓練的 Sentence-T5。
以下是顯示序列推薦性能比較的表格:


